Part 0: Camera Calibration & 3D Scanning
This section documents the camera calibration and 3D object scanning pipeline using ArUco markers for robust pose estimation.
Camera Calibration Results
3D Object Scan
Captured 80+ images of the target object (Pou) with consistent zoom and lighting.


Pose Estimation
Used PnP (Perspective-n-Point) to solve for camera poses from detected ArUco markers.
Key Implementation Details
✓ Robust detection with frame skipping for failed detections
✓ Camera-to-world matrix inversion: c2w = inv(w2c)
✓ Undistortion using cv2.undistort() with optimal camera matrix
✓ Principal point adjustment for cropped regions
Part 1: Neural Field for 2D Images
Training a neural field to fit 2D images using sinusoidal positional encoding and MLPs.
Model Architecture
Training Progression - Fox




Training Progression - My Cat!
Results on cat


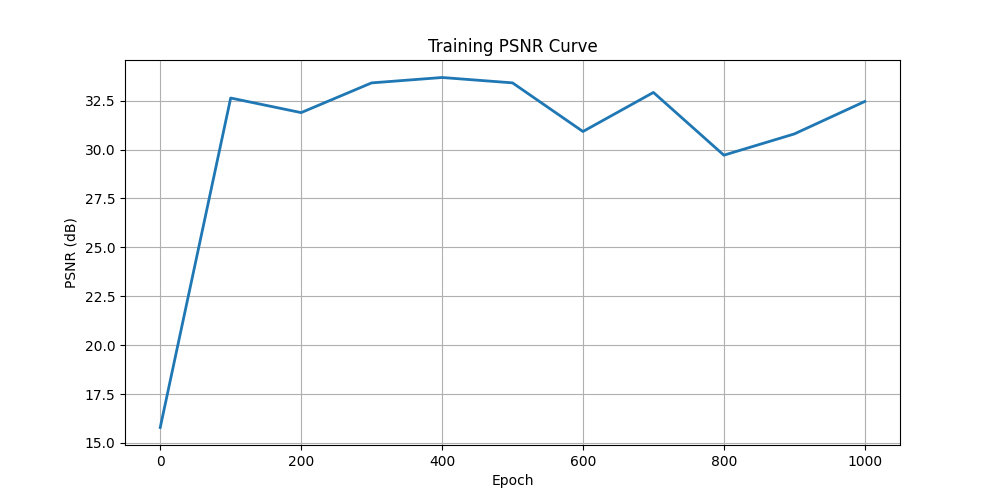
Hyperparameter Study: 2×2 Grid

Limited frequency, small model

Limited frequency, larger model

High frequency, small model
High frequency, large model (Best)
PSNR Training Curve
Part 2: Neural Radiance Field
Training a full 3D NeRF on the given multi-view lego images and pou (my own pictures).
Implementation Details
2.1 - Ray Generation
2.2 - Point Sampling
2.3 - Data Loading
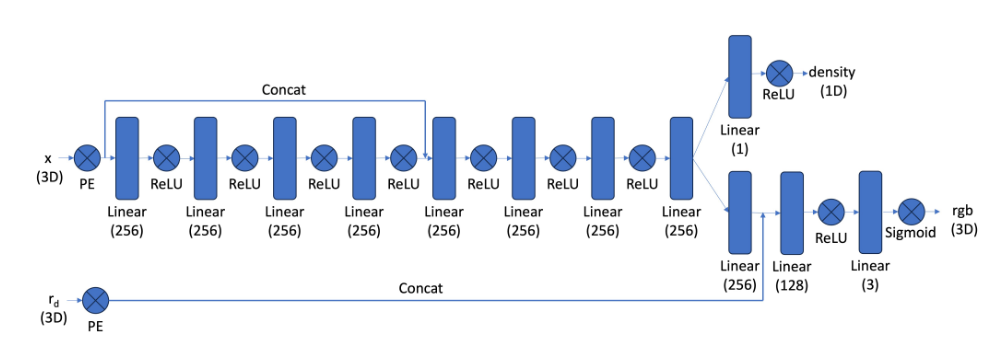
2.4 - NeRF Network Architecture
Network Architecture Diagram
2.5 - Volume Rendering
Visualization: Rays & Samples

Training Progression




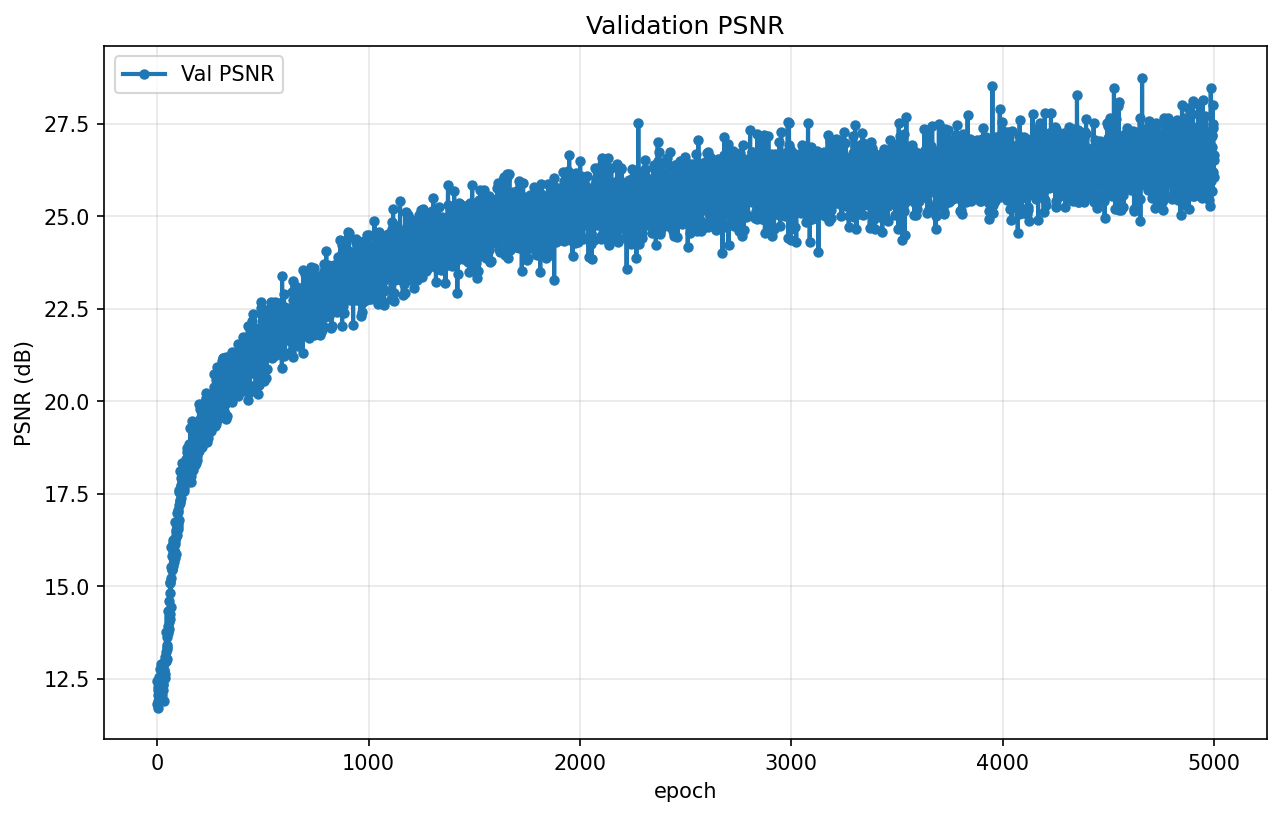
Validation PSNR Curve
Novel View Synthesis - Spherical Video
Novel views rendered from unseen camera poses on a circular trajectory:

Successfully exceeded 23 dB target for full credit
Part 2.6: Training with Your Own Data
Custom NeRF training on a "Pou" using the dataset created in Part 0.
Dataset Information
Hyperparameter Changes
| Parameter | Lego (Reference) | Pou (Our Object) | Reason |
|---|---|---|---|
| near / far | 2.0 / 6.0 | 0.35 / 1.55 | Different camera positions |
| n_samples | 64 | 64 | Same for quality |
| Image Resolution | 200×200 | 320×426 | Better detail capture |
| Learning Rate | 5e-4 | 5e-4 | Standard NeRF settings |
| Training Iterations | 5000 | 5000 | Same for detail learning |
Key Implementation Changes
1. Adaptive Near/Far Planes
Computed optimal near/far from actual camera pose distribution rather than hardcoding
2. Increased Image Resolution
Trained at higher resolution (320×426) for better detail preservation
3. Better Undistortion
Applied optimal camera matrix with ROI cropping to handle lens distortion
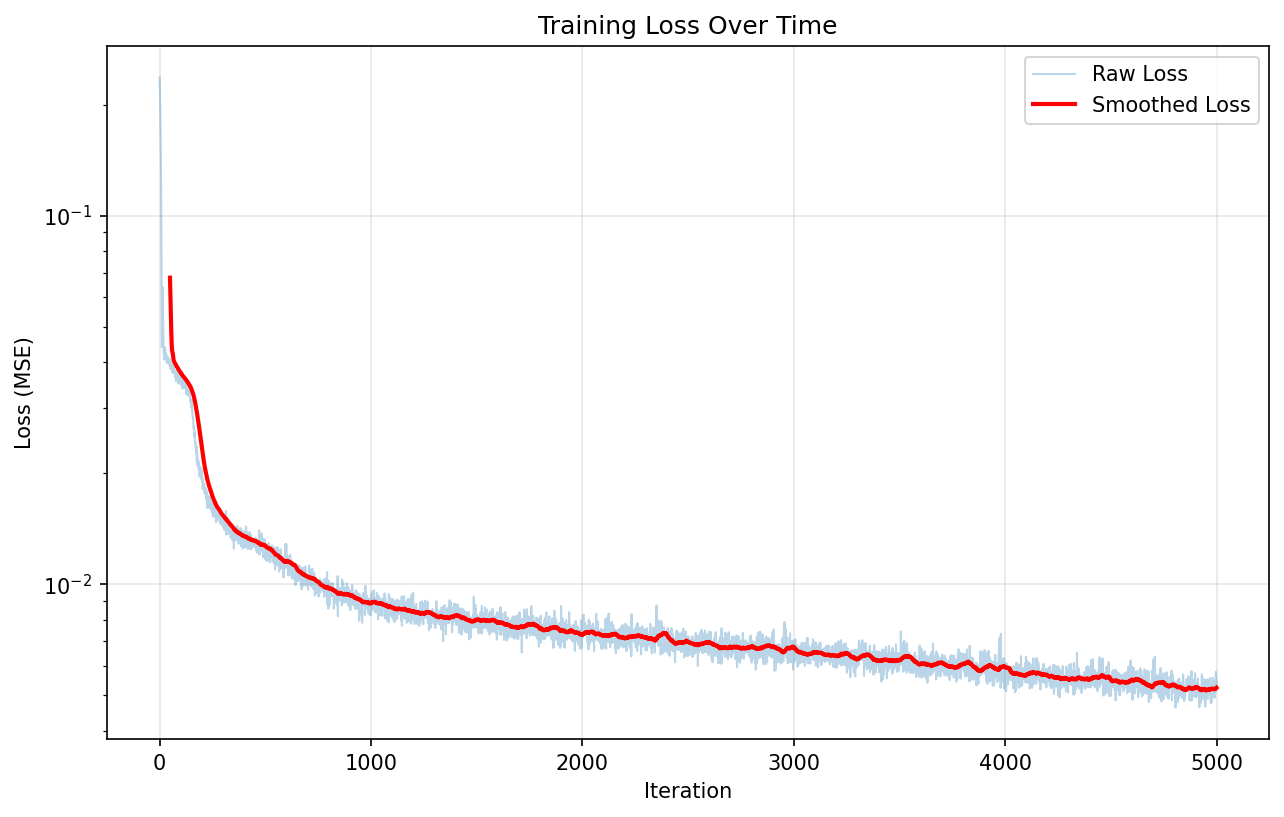
4. Training Loss Tracking
Added loss history to checkpoint files for debugging and visualization
Training Loss Over Iterations
Intermediate Renders During Training




Novel View GIF - Camera Circling Object

Training Discussion
The custom object training presented unique challenges compared to the lego scene:
- Scale Adaptation: The dramatic difference in object size required retuning near/far planes by ~4×
- Lighting Variability: Small variations in capture lighting resulted in artifacts
- Background Noise: Initial training failed with cluttered backgrounds. Using a plain background was essential
- Camera Calibration: Precise undistortion was critical—errors propagated through the entire pipeline
Bells & Whistles: Depth Map Rendering
Rendered depth maps for the Lego scene by compositing per-point depths instead of colors in the volume rendering equation.
Depth Rendering Implementation
Modified Volume Rendering:
Instead of: C = Σ T_i * α_i * c_i
We compute: D = Σ T_i * α_i * t_i
Where t_i is the sample distance along the ray.
Depth Video Results
Visualized in grayscale:

Depth Map Details
Project Summary
✅ 2D Image Fitting
Successfully trained neural fields on 2D images with sinusoidal positional encoding, achieving 30+ dB PSNR.
✅ 3D NeRF Training
Implemented full multi-view NeRF pipeline on Lego dataset, reaching 27.5 dB PSNR target with novel view synthesis.
✅ Custom Object Capture
Created complete camera calibration pipeline and trained NeRF on personal object dataset with novel view rendering.
📊 Technical Skills
• PyTorch neural network implementation
• Camera calibration and pose estimation
• 3D coordinate transformations
• Volume rendering equations
• GPU optimization and batching
🎬 Results
• 2D PSNR: ~33 dB
• Lego PSNR: 27.5 dB
• Novel view quality: Excellent
• Depth rendering: ✓ Complete
• Training time: ~40 minutes for 5000 iters